1. Введение
Задача выделения ключевых слов и терминов из текста возникает в
библиотечном деле, лексикографии и терминоведении, а также в информационном
поиске. Объемы и динамика информации, которая подлежит обработке в этих
областях в настоящее время, делают особенно актуальной задачу автоматического выделения терминов и
ключевых слов. Выделенные таким образом слова и словосочетания могут
использоваться для создания и развития терминологических ресурсов, а также для
эффективной обработки документов: индексирования, реферирования, классификации.
В наших предыдущих работах [2, 1]
мы исследовали методы автоматического выделения двухсловных терминов-кандидатов из текста. В работе [2] мы сравнивали методы
выделения устойчивых словосочетаний, которые используют: 1) статистику
встречаемости пар и отдельных слов в тексте и 2) морфологические
шаблоны-фильтры. Мы сравнили четыре метода: 1) прямой подсчет количества пар (freq); 2) t-тест; 3) χ2-тест;
4) отношение функций правдоподобия (LR). Как показала оценка, методы freq и t-тест сравнимы
по эффективности и могут быть использованы для составления списка
терминов-кандидатов в задачах полуавтоматического формирования терминологических
ресурсов. Основной тип ошибок обоих методов – выделение устойчивых общеупотребительных
словосочетаний, удовлетворяющих шаблонам. В работе [1] для повышения точности выделения терминов мы
предложили использовать Веб в качестве контрастного корпуса, доступ к которому
осуществляется с помощью поисковых машин интернета. Для отделения
терминоподобных словосочетаний от общеупотребительных выражений мы использовали
два параметра: 1) частотность словосочетания и 2) совместная встречаемость
словосочетаний. Использование статистики по Вебу позволило улучшить качество
выделения двухсловных терминов из корпуса статей «Информационного вестника
ВОГиС».
В данной работе мы исследуем различные методы, которые
могут быть использованы для выделения терминоподобных словосочетаний
произвольной длины и структуры. Сложность этой проблемы в том, что для ее
решения статистические подходы не так эффективны: при увеличении длины термина
падает частота его встречаемости, в специализированном корпусе ограниченного
объема термин может встречаться один-два раза. Наша первоначальная идея
состояла в том, чтобы оценить возможность (и сложность) выделения длинных
терминов, которые могут встречаться редко (даже один раз) в исследуемом
тексте/корпусе. Поэтому методы характеризуются высокой полнотой и – как
следствие – низкой точностью выделения терминов. Коль скоро ставится задача
выделения терминов произвольной
длины, делается минимум предположений о структуре термина (при реализации
методов мы ввели ограничение: термины могут состоять только из существительных,
полных прилагательных, причастий и порядковых числительных). Наш подход можно
назвать подходом «чистой доски» (knowledge-poor approach): на этапе выделения терминов-кандидатов мы
используем минимум информации о структуре и составе терминов, не используем
словари, тезаурусы и другие семантические
ресурсы, не делаем привязки к определенной предметной области. В процессе
проведения эксперимента мы скорректировали наш план и провели автоматическую
оценку методов с учетом частоты встречаемости кандидатов в термины (к
сожалению, у нас не было возможности повторно провести экспертную оценку с
учетом частоты встречаемости).
2. Исследуемые методы
Для сравнительного анализа мы выбрали и реализовали
пять методов выделения терминов произвольной структуры.
2.1 MaxLen
Статья [8]
описывает одну из первых систем для автоматизированного извлечения терминологии.
Система LEХTER выделяет
термины из корпуса технических текстов на французском для последующей обработки
экспертом. Первый этап работы системы – выделение максимальных цепочек,
содержащих термины. Эти цепочки определяются негативно: составляется список
слов и знаков, которые не могут
входить в термин. В нашей реализации в качестве таких разделителей мы
рассматриваем знаки препинания, стоп-слова, глаголы, деепричастия; строки между
этими разделителя рассматриваются как кандидаты в термины. Это наиболее простой
из рассматриваемых методов.
2.2 C-value
Метод выделения многословных терминов, предложенный
Frantzi et al. [9], поощряет словосочетания,
не входящие в состав других, более длинных. Встречаемость длинных терминов в
тексте ниже, чем коротких, и метод C-value был предложен для компенсации
этого эффекта. Значение терминологичности рассчитывается так:
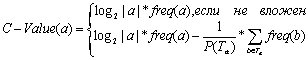 ,
,
где
a – кандидат в термины,
|a| - длина словосочетания, измеряемая в количестве
слов,
freq(a) – частотность a,
Ta – множество словосочетаний, которые содержат a,
P(Ta) – количество словосочетаний, содержащих a.
Легко видеть, что чем больше частота термина-кандидата и его длина, тем больше
его вес. Но если этот кандидат входит в большое количество других
словосочетаний, то его вес уменьшается.
2.3 k-factor
Метод, который мы обозначили k-factor,
предложен в работе [7] и
реализован в системе BootCaT. BootCaT служит для автоматического формирования тематического
корпуса из Веба. Построение корпуса начинается с набора исходных терминов (seed terms). С помощью автоматических запросов к поисковой
машине извлекаются документы, содержащие исходные термины; в свою очередь из
этих документов извлекаются новые однословные
термины (на основе сравнения частот в сформированном корпусе со «стандартным
корпусом»), которые вновь можно использовать в качестве запросов, и т.д.
Финальный корпус и список однословных терминов используется для итеративного извлечения
многословных терминов. Метод можно рассматривать как упрощенный вариант метода C-value:
если более короткий термин-кандидат встречается лишь немногим чаще, чем более
длинный термин-кандидат, в который он полностью входит, то «основным» считается
более длинный вариант. Отбором управляет пороговое значение отношения частот
терминов k (в нашей
реализации, как и в [7],
k=0,7).
2.4 Window
Метод, описанный в [3], мы условно обозначили Window (в оригинальной статье он обозначен TERMS--). Идея метода близка двум предыдущим (C-value, k-factor) – наращивать словосочетания, если более короткие часто встречаются
в составе более длинных. Однако в
отличие от других методов, учитывается не только частота контактных случаев (слова
непосредственно следуют друг за другом), но и совместная встречаемость в окне. На каждой итерации для каждого
элемента списка запоминается его непосредственные соседи и соседи в текстовом
окне. Создаются соответствующие таблицы, вычисляется частотность встречаемости
пар. Далее, предполагается, что если пара элементов (на первом этапе –
отдельных слов) встречается как непосредственные соседи более чем в половине
случаев их появления в одном и том же текстовом окне, то эта пара представляет
собой термин или фрагмент термина. Происходит склейка пары в единый элемент,
таблицы пересчитываются так, как если бы этот элемент был известен с самого
начала, до начала обработки текста, что дает возможность и дальше наращивать
термин. Авторы приводят примеры длинных терминов, полученных этим методом: закон об обязательном страховании
гражданской ответственности владельцев транспортных средств[1], исполнительный орган местного самоуправления.
В нашей реализации размер окна – 9 слов. Если не накладывать ограничений на
частоту встречаемости склеиваемых элементов, то метод объединит уникальные (с
частотой 1) цепочки допустимых слов (т.е. повторит результат MaxLen).
2.5 Синтаксический анализ (АОТ)
Известно, что большинство терминов – это именные
группы (хотя в [6],
например, показано, что номинативность не является исключительной
характеристикой терминов во многих предметных областях). В рамках этого метода
в качестве терминов-кандидатов мы рассматриваем именные группы, выделенные с
помощью синтаксического анализатора. Метод получил название по используемому
анализатору – АОТ [5]. В нашей реализации мы брали синтаксические группы ПРИЛ_СУЩ
и ГЕНЕТ_ИГ. После первичного анализа мы проредили список, исключив группы с однородными
рядами (с запятыми, союзами и/или), а
также группы, не содержащие ни одного русского слова (обычно библиографические
ссылки). Полученные строки мы преобразовывали так, чтобы главное слово именной
группы было словарной форме; другой обработки не проводилось (мы никак не
обрабатывали стоп-слова, поэтому, например, самое частотное из выделенных
методом словосочетаний – то же время).
Метод на основе АОТ – единственный из рассматриваемых, который допускает
наличие предлогов в составе кандидатов в термины.
3. Данные и инструменты
Мы проводили эксперименты на корпусе статей «Информационный
вестник Вавиловского общества генетиков и селекционеров (ВОГиС)» [4], который использовался в
наших предыдущих экспериментах [1].
Корпус содержит 100 статей разных авторов по генетике, селекции, а также
смежным наукам, опубликованных в «Информационном вестнике ВОГиС» с 1997 по 2006
год. Были взяты все статьи журнала за этот период, за исключением редакционных
статей, посвященных юбилеям ученых и памятным датам. Характеристики корпуса:
всего слов – 256 255, без стоп-слов – 179 635. Система АОТ выделила в корпусе 35 737 предложений
(судя по результатам, правила для конца предложения довольно простые: так, комбинация
«точка+пробел» всегда интерпретируется как конец предложения), mystem выделил 27 880 предложений.
Для формальной оценки результатов мы используем
русскую часть словаря терминов по молекулярной и клеточной биологии (http://www.mblogic.net/glossary/),
предоставленную нам Анастасией Барышниковой. Словарь содержит примерно 6 300
входов (строк). Каждая строка может содержать несколько близких терминов,
например: гипотеза гибридной ДНК; модель
гибридной ДНК; гетеродуплексная модель ДНК; полярон-гибридная модель ДНК. Мы
рассматриваем все термины словаря как равноправные (всего – 7 199), распределение
длин терминов словаря выглядит следующим образом: 1 слово – 2 941; 2 слова – 3 110;
3 слова – 798; 4 слова – 214; 5 и больше слов – 136.
Интересно отметить, что словарь содержит достаточно
много «терминов-метафор» (обычно употребляются в кавычках) – как однословных ("аркан", "булава",
"восьмерка", "газон" и др.), так и многословных ("шитье назад", "горячая
точка", "узлы-на-веревке", "счастливые уроды" и
др.). Кроме того, словарь содержит много терминов специфической структуры,
например, с цифрами (1-метил-4-амино-6-оксипиримидин,
4-тиоуридин и др.), греческими и латинскими буквами (α-гетерохроматин, β-талассемия,
D-петли, F-эписома, HKG-бэндинг и
др.), а также сложные термины (например, хронический
остеомиелит длинных костей после огнестрельных повреждений).
Тексты анализировались в формате plain text. Корпус обрабатывался как монолитный документ, без учета
разбиения на отдельные статьи. Морфологическая обработка (кроме метода АОТ) осуществлялась с помощью программы mystem (http://company.yandex.ru/technology/products/mystem/mystem.xml).
4. Методика оценки
Как и в предыдущих работах, мы комбинируем ручную
(экспертную) оценку и формальную оценку по «эталонному списку» (словарю). В
данном эксперименте мы несколько модифицировали методику, описанную в [2, 1].
В соответствии с нашим первоначальным планом, для экспертной
оценки мы брали по 100 кандидатов из полных результатов работы каждого метода
(«длинного списка»). Для C-value мы брали верхушку (top100) отсортированного списка, для остальных методов – 100
случайных строк из списка с учетом длин: 33 – трехсловных, 33 – четырехсловных,
34 – длины пять и более слов. Объединенный «короткий» список содержит 492
строки.
Экспертная оценка организована следующим образом.
Сначала эксперту предъявляется краткое описание предметной области, а также несколько
положительных и отрицательных примеров терминов для данной области. После этого
эксперт, используя простой интерфейс, последовательно для каждого элемента
списка отвечает на вопрос: «Является ли данное словосочетание термином
предметной области?» Варианты ответа эксперта: «да», «нет», «затрудняюсь
ответить», а также «частично» (предъявленное словосочетание содержит термин или
является частью более длинного термина). Список предъявляется эксперту
«порциями» по 10 словосочетаний, порядок предъявления словосочетаний – случайный.
Каждый термин-кандидат оценивается независимо двумя экспертами в данной предметной
области. В случае сильной оценки
термином считается словосочетание, которое оба эксперта признали термином; в
случае слабой оценки только один из
экспертов оценил словосочетание как термин.
Формальную оценку мы провели для «короткого»,
«длинного» и «среднего» списков. В последний попали только строки из «длинного
списка» с частотой встречаемости больше единицы. Мы проводим два типа формальной
оценки на основе 1) четкого и 2) нечеткого сравнения. В первом случае мы
подсчитываем три параметра: 1) точные
совпадения выделенных терминов с терминами словаря, 2) включение терминов словаря в выделенные словосочетания и 3) вхождение выделенного словосочетания в
более сложные (четыре и более слова) термины словаря. При нечеткой оценке мы рассматриваем словосочетания как множества слов,
приведенные к нормальной форме, а близость двух строк определяем как отношение
количества совпавших слов к общему количеству уникальных слов в двух словосочетаниях:
sim (S1, S2) = |S1 Ç S2| / |S1 È S2|. При оценке мы считаем количество
терминов-кандидатов, для которых в словаре есть хотя бы один термин с близостью
³0.5. Примеры близких
терминов по этой метрике приведены в табл. 1.
5. Результаты
Примеры строк, которые были переданы экспертам для
оценки, представлены в табл. 2. Результаты оценки списка из 492 кандидатов в
термины («короткий список») приведены в табл. 3. Оценки экспертов совпали в 54%
случаев. В рамках нашего предыдущего эксперимента мнения тех же экспертов при оценке
двухсловных кандидатов из того же корпуса совпади почти в 80% случаев [1]. Очевидно, что
причина двоякая: длинные цепочки слов менее однозначны и устойчивы, к тому же в
данном эксперименте у экспертов было больше вариантов оценки (четыре против трех
в предыдущем эксперименте). На 27 оценках (5%) мнения экспертов противоположны:
«термин» vs. «не термин».
В табл. 4 приведены результаты формальной оценки
полных результатов («длинный список») обработки корпуса ВОГиС различными
методами. В табл. 5 сведены результаты формальной оценки «среднего списка»
(состоит из строк, которые встречаются в корпусе минимум два раза), в табл. 6
приведены результаты нечеткой оценки кандидатов с учетом их длины в словах.
Графики на рис. 1, 2 построены на основе обработки
списков строк, полученных в результате работы разных методов и упорядоченных по
частоте встречаемости в корпусе. Рис. 1 соответствует top500 всех пяти методов, рис. 2 – «среднему списку»,
полученному с помощью метода C-value (2 466
строк).
Таблица 1. Примеры
вычисления нечеткой близости строк
|
Строка-кандидат |
Термин из словаря |
sim |
|
подавление экспрессии гена |
экспрессия гена |
0.67 |
|
стволовая нервная клетка |
стволовая клетка |
0.67 |
|
центральная нервная система |
вегетативная нервная
система |
0.5 |
|
центральная нервная система |
центральная нервная система |
1.0 |
|
подавление экспрессии гена
мишени |
экспрессия гена |
0.5 |
|
институт химической
биологии |
институт химической
биологии и фундаментальной медицины |
0.5 |
|
действие естественного
отбора |
естественный отбор |
0.67 |
|
полимеразная цепная реакция |
полимеразная цепная реакция |
1.0 |
|
полимеразная цепная реакция |
обратная полимеразная
цепная реакция |
0.75 |
|
российская академия наук |
российская академия
медицинских наук |
0.75 |
|
генетическая дифференциация
популяции |
генетическая структура
популяции |
0.5 |
|
фенотип множественной
лекарственной устойчивости |
множественная устойчивость
к лекарственным препаратам |
0.5 |
Таблица 2. Примеры выделенных строк
|
MaxLen |
|
уникальный
цветовой баркод боковые
передающие цепочки показатели
ассортативности браков фуражная
ценность зеленой массы здоровье
населения алтайского края уникальный
генофонд пушных зверей средним
величинам антропометрических признаков метисы сущность
процессов редукционной эволюции субгеномов органелл разнообразного
типа специализированные дифференцированные клетки геологами
докембрийская летопись развития органического мира Земли |
|
C-value |
|
подавление
экспрессии генов теория
естественного отбора отрицательная
обратная связь центральная
нервная система расщепление
фосфодиэфирной связи экспрессия
гена мишени вторичная
структура рнк регуляция
экспрессии гена боковая
петля рнк множественная
лекарственная устойчивость подавление
экспрессии гена мишени |
|
k-factor |
|
нехватка
ионов марганца Ненецкий
автономный округ резкое
усиление действия ядра
клеток вентральной нейроэктодермы часть
указанных сложных вопросов главный
позитивный эффект миграции частота
наследственных болезней человека период
высокие индексы брачной ассортативности кинетические
характеристики расщепления синтетических фрагментов нарушения
общей устойчивости обмена веществ |
|
Window |
|
мощный
способ идентификации результат
филогенетического анализа уровень
генетического разнообразия наибольшее
разнообразие микросателлитных гаплотипов общие
проблемы физико-биологии упорный
поиск общих законов наследования отсутствие
содержательной интерпретации анализируемых признаков заманчивая
легенда получения зерновой культуры экспериментальная
проверка эффективности селекционного индекса генетическая
характеристика удэгейцев Приморского края |
|
АОТ |
|
значимые
коридоры миграции различные
гибридные комбинации обоснованное
хирургическое вмешательство более
древняя история происхождения судьба
больших групп животных двигательная
активность неонатальных крысят благо
совместных творческих междисциплинарных исследований генетическая
история алеутов Командорских островов резкое
снижение численности коренного населения 2000
полных митохондриальных геномов индивидуумов различного этнорасового
происхождения |
Таблица 3. Результаты
оценки «короткого списка»
|
Оценка |
MaxLen |
C-value |
k-factor |
Window |
АОТ |
|
|
Экспертная, |
слабая |
30 |
62 |
30 |
25 |
20 |
|
строгая |
8 |
24 |
6 |
2 |
5 |
|
|
Экспертная, |
слабая |
44 |
38 |
59 |
53 |
47 |
|
строгая |
14 |
7 |
21 |
13 |
12 |
|
|
Формальная |
точно |
0 |
5 |
0 |
0 |
0 |
|
включение |
66 |
70 |
70 |
71 |
63 |
|
|
вхождение |
0 |
6 |
0 |
0 |
0 |
|
|
нечеткая |
6 |
35 |
8 |
8 |
8 |
|
Таблица 4. Результаты формальной
оценки «длинного списка»
|
Оценка |
MaxLen |
C-value |
k-factor |
Window |
АОТ |
|
размер
списка |
14 970 |
34 370 |
16 986 |
13 845 |
18 772 |
|
точно |
23 |
34 |
27 |
14 |
33 |
|
включение |
10 309 |
23 322 |
11 663 |
9 300 |
10 579 |
|
вхождение |
11 |
29 |
8 |
6 |
17 |
|
нечеткая |
1 613 |
3 640 |
1 836 |
1 382 |
1 712 |
Таблица 5. Результаты
формальной оценки «среднего списка»
|
Оценка |
MaxLen |
C-value |
k-factor |
Window |
АОТ |
|
размер
списка |
743 |
2 466 |
1 949 |
1 352 |
1 190 |
|
точно |
10 |
20 |
21 |
13 |
18 |
|
включение |
492 |
1 643 |
1309 |
883 |
726 |
|
вхождение |
4 |
15 |
5 |
3 |
6 |
|
нечеткая |
150 |
501 |
420 |
267 |
196 |
Таблица 6. Результаты нечеткой
формальной оценки «среднего списка»
с учетом длины кандидатов в термины
|
Длина |
MaxLen |
C-value |
k-factor |
Window |
АОТ |
|||||
|
всего |
близко |
всего |
близко |
всего |
близко |
всего |
близко |
всего |
близко |
|
|
3
слова |
597 |
118 |
1 963 |
409 |
1 609 |
342 |
1 075 |
208 |
987 |
160 |
|
4
слова |
114 |
27 |
375 |
82 |
273 |
69 |
230 |
54 |
171 |
34 |
|
5
и больше |
32 |
5 |
128 |
10 |
67 |
9 |
47 |
5 |
32 |
2 |
|
Всего |
743 |
150 |
2 466 |
501 |
1 949 |
420 |
1 352 |
267 |
1 190 |
196 |
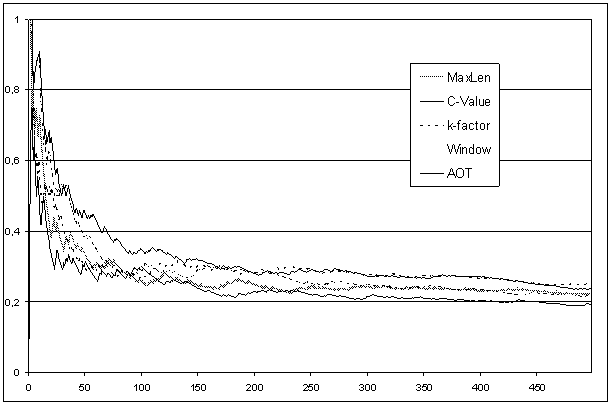
Рис. 1. Доля строк, близких
словарным, в зависимости от длины
списка.
Top500 «среднего
списка», упорядоченного по убыванию
частот
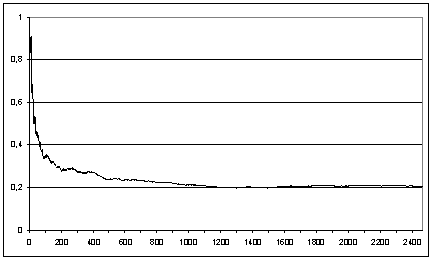
Рис. 2. Доля строк, близких
словарным, в зависимости от длины
списка.
«Средний список» метода C-value, упорядоченный по
убыванию частот (2 466 строк)
6. Выводы
На основе анализа результатов можно сделать вывод, что
сравниваемые методы дают в целом похожие результаты. Несколько лучше ведут себя
методы, учитывающие вложенность терминов (C-value, k-factor). Выделение
именных групп на основе синтаксического анализа без дополнительных ограничений
дает худший результат (АОТ). Сопоставление результатов экспертной и
формальной оценок (см. табл. 3) позволяет сделать вывод, что формальные методы
годятся для сравнения больших списков кандидатов в термины.
Учет частоты встречаемости строк существенно не
повышает качество выделения терминов, если нас интересует хоть сколько-нибудь
значительная полнота: на основании формальной оценки (см. рис. 1) можно
предположить, что точность деградирует очень быстро (во всяком случае, для
небольшого корпуса текстов). При этом в области редких строк «всегда есть
что-то интересное»: примерно для каждой пятой строки на большом диапазоне
списка есть близкий словарный термин почти постоянна (см. рис. 2).
Распределение длин терминов из словаря по молекулярной
и клеточной биологии, а также сильное ухудшение качества выделения длинных
терминов (5 и более слов) подсказывает, что повысить качество и обеспечить
хорошую полноту можно с помощью шаблонов для трех- и четырехсловных терминов.
Как предлагается в других работах (например, [3]), использование семантических словарей сочетаемости,
продуктивных и непродуктивных слов может существенно повысить качество
выделения и сборки терминов.
Благодарности
Мы благодарим Анастасию Барышникову и Татьяну Струкову,
которые приняли участие в оценке. Кроме того, мы благодарим Анастасию за
предоставленный словарь, а также анонимного рецензента за ценные замечания по
содержанию работы.
Литература
1.
Браславский П., Соколов Е. Автоматическое извлечение терминологии с
использованием поисковых машин интернета // Компьютерная лингвистика и
интеллектуальные технологии: Труды Междунар. конф. Диалог'2007. М.: Изд-во
РГГУ, 2007. С. 89-94.
2.
Браславский П.,
Соколов Е. Сравнение четырех методов автоматического извлечения
двухсловных терминов из текста // Компьютерная лингвистика и интеллектуальные
технологии: Труды Междунар. конф. Диалог'2006. М.: Изд-во РГГУ, 2006. С. 88–94.
3.
Добров Б.В.,
Лукашевич Н.В., Сыромятников С.В. Формирование базы терминологических
сочетаний по текстам предметной области // Электронные библиотеки:
перспективные методы и технологии, электронные коллекции: Труды пятой
Всероссийской научной конференции (С.-Петербург, 29-31 октября 2003 г.), 2003.
С. 201–210.
4.
Информационный вестник ВОГиС, http://www.bionet.nsc.ru/vogis/
5.
Синтаксический анализ. Проект АОТ, http://www.aot.ru/docs/synan.html
6.
Шелов С.Д. Терминоведение: семь вопросов и семь
ответов по семантике термина // НТИ. Сер. 2. Информационные процессы
и системы, 2001. №2. С. 1-11.
7.
Baroni M., Bernardini S. BootCaT:
Bootstrapping Corpora and Terms from the Web // Proceedings of LREC 2004.
8.
Bourigault D. Surface Grammatical
Analysis for the Extraction of Terminological Noun Phrases // Proc. of
COLING-92,
9.
Frantzi K., Ananiadou S., Mima H. Automatic
recognition of multi-word terms: the C-value/NC-value method // Int J Digit
Libr (2000) 3: 115–130.